Optimal Stall Recovery via Deep Reinforcement Learning for a General Aviation Aircraft
Abstract
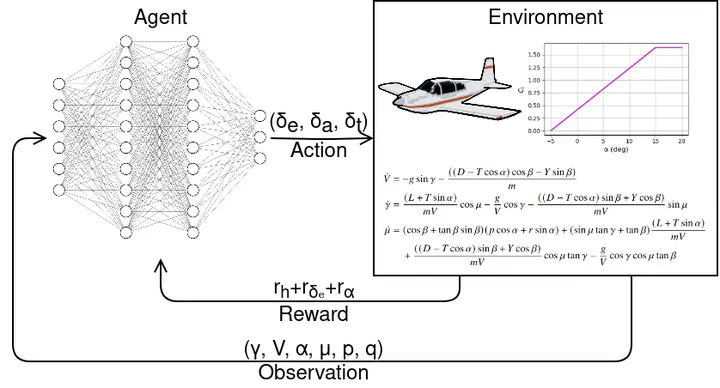
Stall is a hazardous region of the flight envelope for fixed-wing aircraft, in which a high angle of attack causes flow separation from the main wing. Indeed, inadvertent stalls are a major co-factor of fatal accidents in general aviation aircraft, and applying correct stall recovery actions is fundamental to minimizing altitude loss and thus the risk of ground collision. This paper studies the optimal stall recovery problem, whereby a control policy for control surface deflections and throttle is computed with the goal of minimizing total altitude loss for a general aviation aircraft. The optimal control problem is formulated and cast as an infinite horizon Dynamic Programming (DP) problem. To circumvent the curse of dimensionality, characteristic of exact DP algorithms, the Proximal Policy Optimization (PPO) algorithm is considered, a sampling based Deep Reinforcement Learning algorithm that can handle large continuous state-action spaces. The approach is first validated by comparing the results from PPO with those from Value-Iteration, an exact DP algorithm, on a reduced order problem, showing that indeed PPO converges to the optimal policy. PPO is then applied to the stall recovery problem computing the optimal policy for control surface deflection and throttle inputs. The results presented in this study confirm empirically developed guidelines for stall recovery of general aviation aircraft, and also shows the criticality of correct elevator and throttle management in the minimization of altitude loss, with as much as a 30% increase in altitude loss if application of full throttle is delayed by as little as 0.75 seconds In addition to the quantitative results and analysis presented for the stall recovery problem, this work suggests that PPO could be applied to other challenging loss of control and upset recovery problems involving full aircraft degrees of freedom opening up new lines of research in fixed wing loss of control.
Type
Publication
AIAA SCITECH 2024 Forum